
Getting started with AI / ML
Getting started with AI / ML
LLMs to be specific

“How to get started with AI/ML and LLMs to be specific” is a question I was asking myself some time ago and since I posted the MLOps series intro I received from others.
It’s a fair question and particularly hard one to pin down, especially in an era of information overload regarding AI.
I am not an expert nor do I claim to master the landscape, I’m nowhere near actually, I am trying to figure it out like you are and here I want to share what I would tell if my past self was asking me the same question based on what I know today.
I will try to explain/reference each area by various complexity level so you can choose which one is more relevant to your journey of AI and build from there on.
Scope
AI is such a vast field and breakthroughs are happening in many areas however in this article we will focus on Generative AI and specifically LLMs (Large Language Models) such as GPT-3, GPT-4, BERT, Llama 2 and so on.
AI
Artificial Intelligence (AI) is like a big playground in the world of computer science, where the aim is to create smart machines/systems that can do things usually expected of humans and more.
They can learn from experiences,
Think through problems,
Understand languages,
and maybe even spot and fix their own mistakes.. woooo :👻
AI is a broad field but let be frank we are here because of the current outburst in the field of generative AI:
Generative AI
Here are a few answers from simpler to detail.
It’s an AI that generates stuff.
Its Software can create plausible and sophisticated text, images, and computer code at a level that mimics human ability. 1
It's a subset of AI that focuses on generating novel data samples from the same distribution as some existing data.
Why did it suddenly blow up
To understand that let’s maybe understand the basics of AI.
Neural Networks: AI has been worked on for many years, one way of building AI is by a method called neural network.
It teaches computers to process data in a way that is inspired by the human brain. It uses interconnected nodes or neurons in a layered structure.
GPT-3 and GPT-4 are giant neural networks developed by OpenAI.
How is this topic relevant to me?
This topic is relevant for you if you want to understand basic building blocks inside an AI.
How Deep should I go on this topic?
Basic: If you are not sure, choose this path. Establishing a basic understanding of it is enough and you can come back to the topic once you have chosen your favourite area of AI and if that area requires more advanced understanding.
Sources: Recommended read for this level. This covers a very high level intro.
Intermediate: A deeper level is needed if you want to understand the inside architecture of AI systems in more depth. and then explore various architectures of neural networks.
Sources: Recommended Read. Though some may this find this basic.
Advance: an expert level understanding is needed to build AI models or contribute to existing ones. Reading well referenced courses and latest
https://arxiv.org/ publication on the topic could be helpful.
Transformer
AI was being worked on for many years so what caused this recent breakthrough and we jumped from being in Tech-Era to AI-Era?
Well, it is due to something called “Transformer“.
Transformer is a type of neural network architecture; introduced in the paper "Attention is All You Need" by Vaswani et al., in 2017. The transformer architecture has since become a foundational component in the field of deep learning, particularly for handling sequential data like text.
Is this topic relevant to me?
If you are interested in learning how LLMs work then yes.
Basic: for an easy entry into the concept.
Sources:
This is a very nice visual story by the Financial Times explaining the concept in the simplest possible way.
I really like this one by Nvidia, it may be a bit more than basic but it’s easy to read and understandable without requiring too much prior knowledge.
This article by
is a very nice starting point for demystifying basic concepts.
Intermediate/Advanced: I want to dive deeper:
Sources:
This article by Stephen Wolfram was actually one of the first ones I read to help grasp LLMs and Transformers. Highly recommended, that however go through the basic ones to have a more easy dive into this one.
Building Products with LLMs
Foundation models (and LLMs) are pre-trained on large masses of data. These models serve as a foundational layer, upon which additional task-specific models, adaptations, or applications can be built.
In simpler terms, foundation models can be regarded as generalists rather than specialists. But what if we need a specialist? The power of foundation models lies in their flexibility to morph into task-oriented experts. Here are three (out of many) methodologies to tailor foundation models to specific needs which we can use and build products from:
Prompt Engineering:
Definition: Prompt engineering involves designing precise input prompts to guide the model towards generating desired outputs. It involves selecting appropriate keywords, providing context, and shaping the input in a way that encourages the model to produce the desired response and is a vital technique to actively shape the behavior and output of foundation models.
Use Cases: This method is appropriate in scenarios where the foundation of the model is enough and we don’t desire a modification to it, or when other techniques are rather expensive.
Examples: A prime example would be crafting prompts for GPT like “Translate the following English text to French: {text}” can lead to accurate translations without additional training.
Sources:
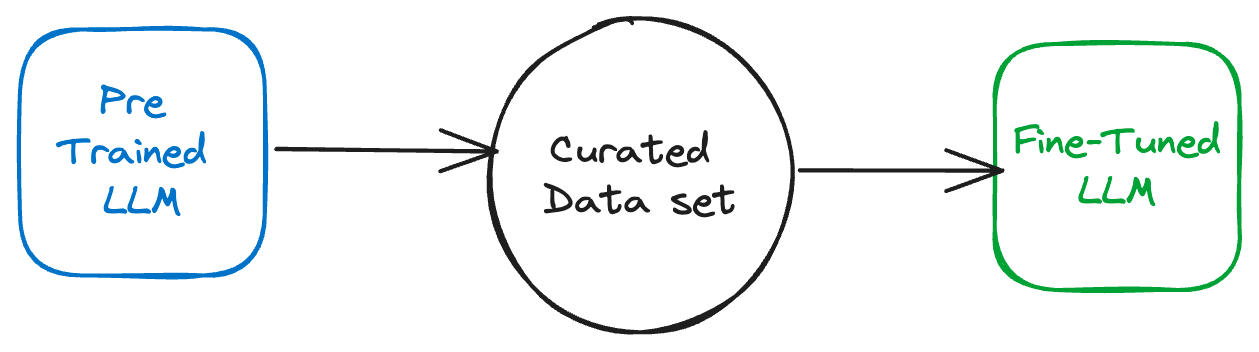
Fine-Tuning:
Definition: Fine-tuning adjusts the pre-trained model parameters on a smaller, domain-specific dataset, thus sharpening the model’s abilities for specialized tasks.
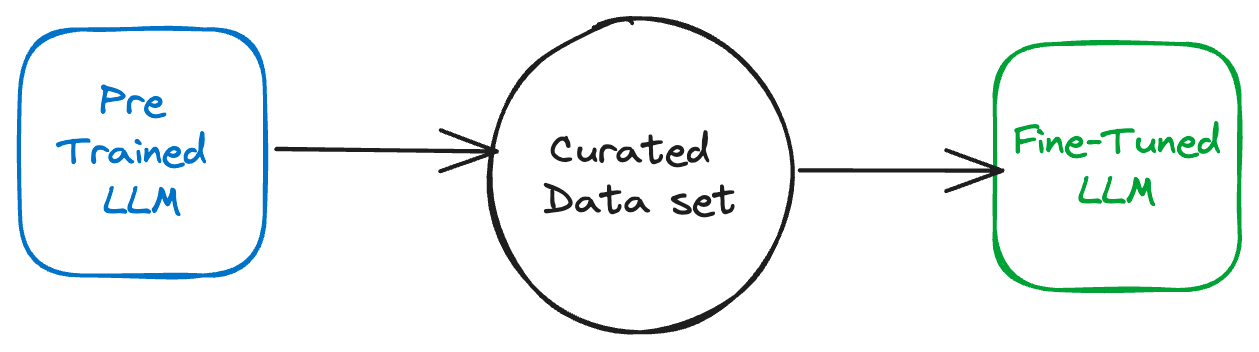
Use Cases: It’s particularly useful when there’s a need for the model to understand domain-specific terminology or when high accuracy is a priority.
Example: Fine-tuning LLM for legal document summarization;
Where we collect a dataset of legal documents along with their summaries. These could be court rulings, contracts, or legislation texts, for instance.
Use this dataset to fine-tune a pre-trained language model. During fine-tuning, the model learns to understand the legal terminology, the common patterns in legal text, and the essential information that needs to be included in the summaries.
Sources: hugging face and more granular by Philipp Schmid
Retrieval Augmented Generation (RAG):
Foundation models are usually trained offline, making the model agnostic to any data that is created after the model was trained. 2
Definition: RAG combines the strengths of retrieval-based and generative models. It retrieves relevant information from an external corpus before generating a response, thus supplementing the generation process with external knowledge.
Use Cases: Ideal for tasks that need additional background knowledge or facts that were not present in the pre-training data.
Examples: Implementing RAG for question-answering systems in a technical support context, where the model fetches answers from a database of known solutions before generating a tailored response.
Learning Source: This hands-on exercise is a better way to learn this topic than just theories
Choosing between RAG, Fine-Tuning, and so on, and understanding when to use each is a compelling subject. I'm in the process of crafting a dedicated blog post on this very topic. Keep an eye out!
While the methodologies mentioned above provide some of the most popular and effective ways to utilize the capabilities of LLMs for product development, they are not the only ones. More advanced and diverse approaches to building AI-driven products involve techniques such as training models entirely from scratch, combining multiple foundation models, leveraging hybrid architectures, and more.
https://ig.ft.com/generative-ai/
https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html